“Managing software” and “managing software development” is a complex subject which is surrounded by a lot of bruhahah and fancy marketing presentations full of neat-looking flow charts and ambiguous terminology. I’m trying to establish some common vocabulary so we sort-of know what we’re talking about.
We can identify several common activities which apply to most software management processes.
- versioning. Sane developers use a version control system such as subversion to keep track of the changes to source code, especially when there’s multiple developers working on the same software.
- building. The wikipedia description talks about converting files from one form into another, which is one part of the process for constructing software. Since we’re talking about a “directed transformation” (we’re mostly looking at compilation, not decompilation), we use a term to indicate this. In analogy to what engineers working in the physical world do, we tend to talk about a “build tool” or “build system”.
- testing. Usually considered part of “the build”, there are often automated tests for software (and sometimes also manual tests) to verify that the software was built/installed/packaged/configured correctly. Sometimes, it is possible to skip the tests. Sometimes it is hard to run them or interpret the results.
- packaging. Once software has been built (or, also common, before it has been built), we often want to share it with others (or sell it). To this end, we tend to package up the software into some kind of “archive format”.
- configuring. Source code is often written to be able to function in a variety of environments, such as on different operating systems or even on different kinds of hardware. Some software may also function differently depending on what other software is installed on the system already. Lastly, users may wish to customize how the software behaves or is instaleld. So we often have to configure “the build” to do the proper things for any particular environment.
- installing. After software has been built and configured, we often copy it into specific locations on the target system, register it with the operating system as a service, or something simliar.
- distributing. After we package software (or, also common, before we package it), we share it with others by publishing it on the internet, a cd-rom or similar medium, or by submitting our changes to a centralized or
decentralized version control system (called a “checkin”).
Marketing blah blah
“SCM” is a marketing term often used by pointy-haired bosses in the business of selling “software consultancy” services to other pointy-haired bosses. It stands for software configuration management, and its mostly about “managing” these different activities by following some sort of process, and integrating that “software process” into a “business process”.
There’s a lot of different terms and phrases for describing this kind of thing, such as CMM(I) (levels 1 through 3) a whole bunch of ISO standards, as well as fancy terms such as “eXtreme Programming” or “agile development” for when you
know CMM is a silly phrase yet you still need to sell your company as “conforming to” or “applying” some sort of process.
There’s also something akin to the “open source software management process” which involves ideas such as “automated everything” and “just use apt-get” which is generally a much more sensible (if under-documented) “process”. Karl Fogel
has written a book on producing open source software which goes into this to some detail (http://producingoss.com/html-chunk/index.html).
Real life software management
In reality, no-one in the real world developing real software really follows the fancy flow charts. A rather generic SCM flowchart which incorporates many common process looks roughly like this:
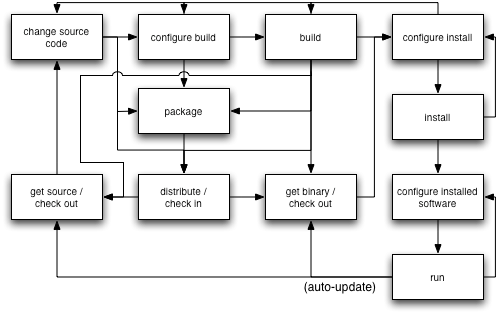
In this chart, each and every step could probably be skipped or replaced by a “no-op”, and some arrows are followed more commonly than others.
For example, most software developers tend to follow an iterative process when writing code. They’ll “switch into development mode”, change some source, rebuild and test the change, change some more source, rebuild and test, check in
the changes, rebuild and test, create a distribution package, “switch to production mode”, get the distribution, build and test it, do some configuration, rebuild, then install. Then when they get called in the middle of
the night because the software just crashed, they’ll often not follow any kind of process at all and do things like change the running program on the live machine.
If the above paragraph sounds confusing, trust me, all this stuff is. “Managing software” is not a simple task. No wonder the average programmer or system administrator has a strong caffeine addiction.
