Lets say you write component-oriented, loosely coupled, design-by-contract (java) software and you do rigorous unit testing. How do you organise your codebase?
Here’s one way.
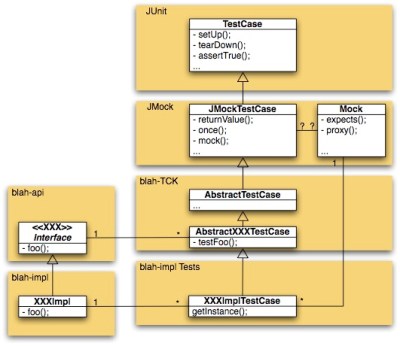
- Put all of your (work) interfaces, and everything referenced from those interfaces (like simple data beans and exceptions) in an “API” package. If you use a tool like Maven to split your code up into small libraries, make the API package into a seperate library. The main reason for this is that you (hopefully) make it possible for packages that use your library to compile and link against only the API package, which promotes loose coupling.
- Optionally put “support code” which will only ever really need one implementation or will be shared by implementations in an “SPI” package. If your library has a “implementation registation” or brokering interface such as the JDBC driver manager, it is likely a good candidate for this SPI package. (The abbreviation SPI stands for Service Provider Interface). Either package this SPI package with your API package, or provide it seperately.
- Write abstract test cases for each of your (work) interfaces. These abstract test cases are specifically geared at testing the contract promoted by the (work) interfaces, and not things like setup, initialization or destruction code. (If you write your code test-first, you’ll write these tests before you start on the work interfaces). Since JUnit (at least for 3.x) pretty much requires that you use subclassing of its
TestCaseclass, it may make sense to introduce a common abstract base test class immediately (I tend to have an abstract base test case for handling the “no test result” result that junit 3.x does not natively support). This kind of abstract test case might look like this:public abstract class AbstractFooXXXTestCase extends AbstractFooTestCase { protected abstract FooXXX getInstance(); public void testFooNeverReturnsNull() { assertNotNull( getInstance().foo() ); } }You can keep these TCK tests right next to the concrete tests for your (first) implementation code, or you can make it into a seperate package.
- Create concrete subclasses for these abstract test cases, which feed the superclass an instance of an implementation of the (work) interface that is being tested. These concrete classes are responsible for creating mock objects of the dependencies, doing any neccessary initialization, etc.
- Create the implementation code that is needed to make the concrete test cases compile and run successfully. If you’ve prepared a seperate “API” package, you might want to consider naming this package the implementation (or “impl” for short) package. If there’s a specific technology used for this implementation (like a specific database backend), you might want to name the package after that, instead of just using “impl”.
- The SPI package probably needs some test cases of its own. These are not a part of your TCK. Keep them close to the SPI code.
- Rinse and repeat. When doing incremental development, you’ll typically add a test to one of the TCK test classes, possibly modify the API and implementation package to make sure so everything compiles once more, re-run the concrete test suite to make sure the newly added test fails, then modify the implementation code and re-run the tests until all the tests pass again. When doing more of an up-front design, its still a good idea to start codifying design contracts for your (work) interfaces in a TCK suite as soon as possible, as a properly written TCK is probably a bit less ambiguous than most specification documents.
Note that, for bigger projects with multiple implementations, the exposed interfaces of the SPI and TCK packages need to be treated with similar care as those in the API package, since adapting implementation test cases to changes in the TCK might be too much effort otherwise.
I’ve been using this kind of code organisation for quite a while now (first for the jicarilla.org codebase, later also for commercial projects). PicoContainer uses it too, and it might very well be where I borrowed the idea from.
