Before we go and talk about a better make, we should make sure we define what make actually is. Its a rather simple tool for transforming files from their source form into something else and doing some amount of dependencies tracking. Its a “dependency maintenance tool” and a “software construction tool” which is at its best when used together with other tools to form a “build system” and/or a “package management system”.
(This article is part of a series on build tools.)
Make as a tool
The wikipedia page on make starts off like this:
make is a utility that automates the process of converting files from one form to another, doing dependency tracking and invoking external programs to do additional work as needed. Its dependency tracking is very simple and centers on using the modification time of the input files. Most frequently it is used for compiling source code into object code, joining and then linking object code into executables or libraries. It uses files called “makefiles” to determine the dependency graph for a given output, and the build scripts which need to be passed to the shell to build them. The term “makefile” stems from their traditional file name of “makefile” or (later) “Makefile”.
That’s a rather good, if compact description. There are many variants of make available, all with slightly different features. The ones in most common use today are GNU make and BSD make.
Make as a part of a process
There is more to software than transforming source files into object files. I’ve written more about the software management process. Make is often the “driver” program for several of these stages. To build software, you often just type make. To test it, you type make test. To package software up into a release, you’ll type make dist. To distribute it, you’ll type make publish. To install it, you type make install.
Make really is optimized primarily for the “build” step, e.g. for the actual sourcefile to object file transformations. But since it uses the shell for executing commands, and the shell is the usual way you execute commands (yeah yeah, I know there is such a thing as a GUI), its real easy to hook up commands for doing most of the other stuff, too, and its possible to implement rules such as if a source code file changed, recompile the output files that are created from that file, then rerun the tests that test those output files, even if it quickly becomes quite complex and awkward to maintain those rules.
Using make for building software
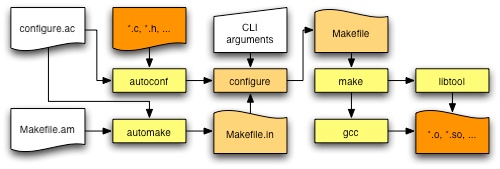
Now, even when using make for just “the build” it usually does not operate in isolation. In the more-or-less standard way make is used to build a piece of “native” software, the sequence of commands is actually more like ./configure; make. Here, configure is a (rather extensive) shell script.
Since writing a really complex, portable shell script is very hard, many developers of C/C++ software use GNU Autoconf and the other parts of the GNU build system (autoconf, automake, and libtool) to assist them. These tools help to with generating the configure script and the Makefile. The complete process looks something like this:
 /div>
/div>
So to make effective use of make for builds of software of realistic complexity which must build on a variety of platforms, we have to add several more steps of macro expansion, introspection, transformation, compilation, etc. Automake and autoconf are usually run by the original package developer, and then the generated configure script and generated Makefile are shipped to the end user. This means that the automake and autoconf dependencies (like perl and the GNU version of the M4 macro language) are not needed by the end user. However, since the configure script and Makefile are very complex, if the end user wants or needs to make changes to the build process, they usually still need to have automake and autoconf installed.
Note that while the GNU build system has some support for software written in languages such as perl, python or java, developers using those languages tend to not use make at all, instead opting for a language-specific tool.
Using make for other tasks
Any kind of task which involves the transformation of one kind of file into another kind of file is something where make can be very useful. For example, make can be used to package up generated code into a tarball, or to invoke any of the multitude of latex tools out there to generate HTML or PDF documentation.
Make is also often used for tasks that have little to do with transformation of input files into output files, but which are somewhat related to the more general process of dealing with software. For example, many Makefiles support an install target, which copies compiled software into a location on the filesystem where it can be easily invoked. Similarly, make is the basis of the BSD ports system.
How make interacts with packaging systems
Many linux distributions have a special kind of “packaging format” which adds its own “metadata” to a particular piece of software. This metadata describes what commands should be invoked to make the software compile and install successfully on the target platform. Several management tools are usually provided for managing this kind of metadata and/or these kinds of packages. In most cases, these tools at some point in their execution invoke make to do the actual software build. The BSD ports system is an interesting exception — it is completely based around make, and hence make tends to be used to invoke itself.
Here’s a picture showing the relationship between make and many common packaging tools:
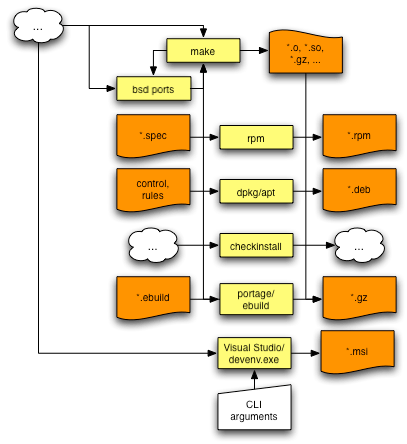
(Note how building software for windows generally does not involve make. Also note how messed up package management on windows generally is. Coincidence? I don’t think so.)
Make as something to improve on
Make is rather simple, stable and mature software available on just about every computing platform out there, and installed by default on about every operating system but Microsoft Windows. While make is primarily optimized for building object files from source code and tracking dependencies between object files and the corresponding source files, it is flexible enough to be integrated with and usable for many other tasks of the software management process.
So what is there to improve on? Together with the previous two posts, this post should provide enough “background” so I can start compiling a list…
April 17 update: minor formatting updates and reference to the overarching series.
